
Github
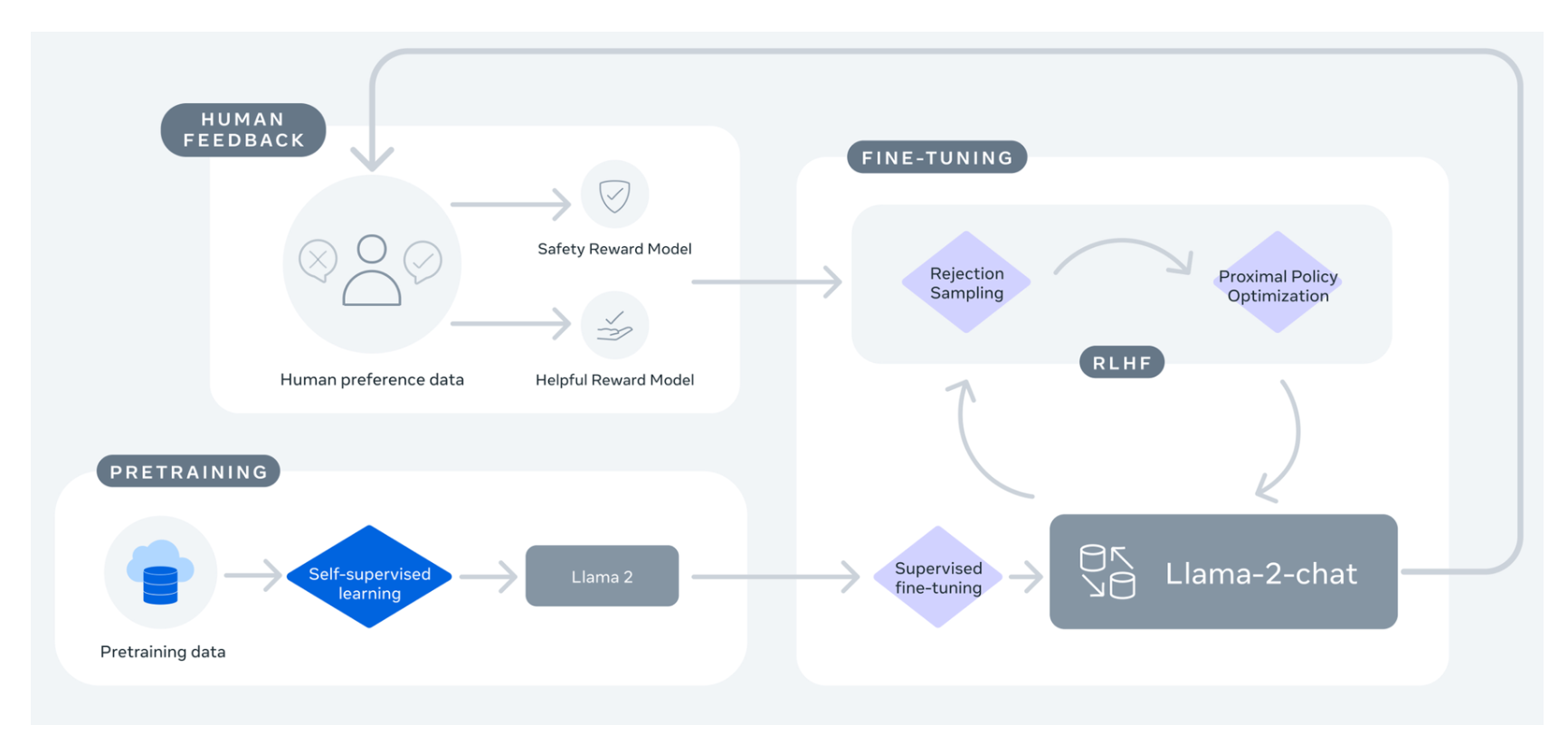
In this section we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2 on simple hardware and show how to fine-tune the 7B version of Llama 2 on a single. Llama 2 is here - get it on Hugging Face a blog post about Llama 2 and how to use it with Transformers and PEFT LLaMA 2 - Every Resource you need a compilation of relevant resources to. Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with comprehensive integration. Well use the LLaMA 2 base model fine tune it for chat with an open-source instruction dataset and then deploy the model to a chat app you can share with your friends. Getting Started with LLaMa 2 and Hugging Face This repository contains instructionsexamplestutorials for getting started with LLaMA 2 and Hugging Face libraries like transformers..
Llama 2 is being released with a very permissive community license and is available for commercial use The code pretrained models and fine-tuned models are all being. Code Llama is a family of state-of-the-art open-access versions of Llama 2 specialized on code tasks and were excited to release integration in the Hugging Face ecosystem. Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with comprehensive integration in Hugging. In this tutorial we will show you how anyone can build their own open-source ChatGPT without ever writing a single line of code Well use the LLaMA 2 base model fine tune. Llama 2 is here - get it on Hugging Face a blog post about Llama 2 and how to use it with Transformers and PEFT LLaMA 2 - Every Resource you need a compilation of relevant resources to..
5 rows The native context length for Llama 1 and 2 are 2024 and 4096 tokens You should NOT use a. What is the maximum token limit of llama Is it 1024 2048 4096 or longer. All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have. Llama 2 supports a context length of 4096 twice the length of its predecessor. Llama 2 models offer a context length of 4096 tokens which is double that of. Insights New issue LlaMA 2 Input prompt 2664 tokens is too long and exceeds limit of 20482560 525. Llama 1 released 7 13 33 and 65 billion parameters while Llama 2 has7 13 and 70 billion parameters. It was made adjustable as a new command line param here..
In contrast OpenAIs GPT-4 a multimodal marvel can juggle both. A bigger size of the model isnt always an advantage. Llama 2 tokenization is longer than ChatGPT tokenization by 19 and this needs to be taken into. Yet just comparing the models sizes based on parameters Llama 2s 70B vs. According to Similarweb ChatGPT has received more traffic than Llama2 in the past month with about. ChatGPT-4 significantly outperforms Llama 2 in terms of parameter size with. 6 min read Individuals with even a rudimentary understanding of AI know of the emergence of large..

Medium





Comments